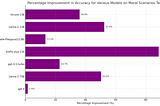
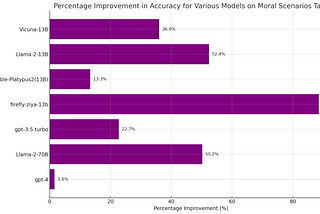
PinnedCorey MorrisMMLU’s Moral Scenarios Benchmark Doesn’t Measure What You Think it MeasuresIn examining the low performance of large language models on the Moral Scenarios task, part of the widely-used MMLU benchmark by Hendrycks…6 min read·Sep 27, 2023--1--1
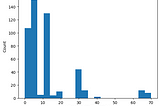
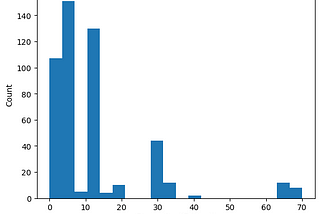
PinnedCorey MorrisPreliminary Analysis of MMLU-by-task: Insights from the Evaluation of Over 500 Open Source ModelsRecently Hugging face released a dataset of evaluation results for the Measuring Massive Multitask Language Understanding (MMLU)…5 min read·Aug 7, 2023----